쿠키런 킹덤 서버 아키텍처 1
Actor Model에 대해서 정리하며 포스트를 쓰려다가 예전에 봤던 NDC21-프로그래밍, 쿠키런 킹덤 서버 아키텍처 뜯어먹기가 떠올라서 리뷰해보려고 한다. 서버 아키텍처에 대해 많은 내용을 배울 수 있는 자료라서 좋은 공부가 될 것 같다.
일단 영상의 주요 내용은 다음과 같다. (영상 1분 16초 참고)
- Stateful vs. Stateless, and Actor Model
- CRUD vs. Event Sourcing
- 함수형 프로그래밍과 DSL로 콘텐츠 구현
- 유저간 상호 작용 구현하기: 2PC vs. SAGA
- 이벤트 기반 아키텍처를 바탕으로 확장하기
이번 포스트에서는 첫번째 내용을 다뤄보려고 한다. 첫번째 내용만 해도 다룰 이야기가 참 많다.
Stateful vs. Stateless
Stateful 서버와 Stateless 서버는 서버가 상태(state)를 저장하는지로 구분한다. 서버라고 하면 백엔드 시스템 전체를 말하는 것인지, API 요청을 처리하는 프로그램을 말하는 것인지 애매한 지점이 있다. 여기서 서버란 클라이언트의 요청을 받아 응답을 생성하는 웹 어플리케이션을 말한다.
단순히 정적 파일(static files)만 배포하는 서버가 아니라면 대부분의 경우 상태를 저장하는 기능이 필요하다. (데이터를 저장한다고도 한다.) 소셜 미디어를 운영하는 경우 사용자, 게시물 등을 PostgreSQL과 같은 데이터베이스에 저장하는 경우가 일반적일 것이다. 사용자의 세션을 관리하거나 퍼포먼스를 향상시키기 위해 캐싱을 하는 경우 Redis같은 In-memory DB를 사용할 수도 있다. 아니면 정말 단순하게 웹 어플리케이션 프로세스 자체에 데이터를 저장할 수도 있다.
정리해보면 상태가 저장되는 위치는 웹 어플리케이션의 내부와 외부로 구분될 수 있다. 웹 어플리케이션의 내부에 저장된다는 것은 웹 어플리케이션 프로세스를 뜻하고, 외부는 PostgreSQL, Redis처럼 자체적인 프로세스를 가지는 저장방법을 말한다. 이 것이 일반적으로 통용되는 Stateful 서버와 Stateless 서버의 구분 지점이다. Stateful 서버는 웹 어플리케이션 프로세스 자체에 상태를 저장하고, Stateless 서버는 프로세스에 어떤 상태도 저장하지 않는다.
서버 구조를 설계하는 데 한 가지 이상의 방법이 있다는 것은 각각 장단점이 있다는 뜻이다. 이를 잘 파악해야 목표에 맞는 서버를 설계할 수 있다. Stateful 서버와 Stateless 서버의 장단점을 살펴보자.
Stateless Server
Pros
Stateless 서버를 먼저 살펴보도록 하자. Stateless 서버는 Pure Function으로 추상화가 가능한데, 상태가 없다는 말은 Side Effect를 없앨 수 있다는 뜻이기 때문이다. 서버가 Pure Function이 되면 Input에 대한 Output이 항상 동일해지기 때문에 서버를 아무런 제약없이 복제할 수 있게 된다.
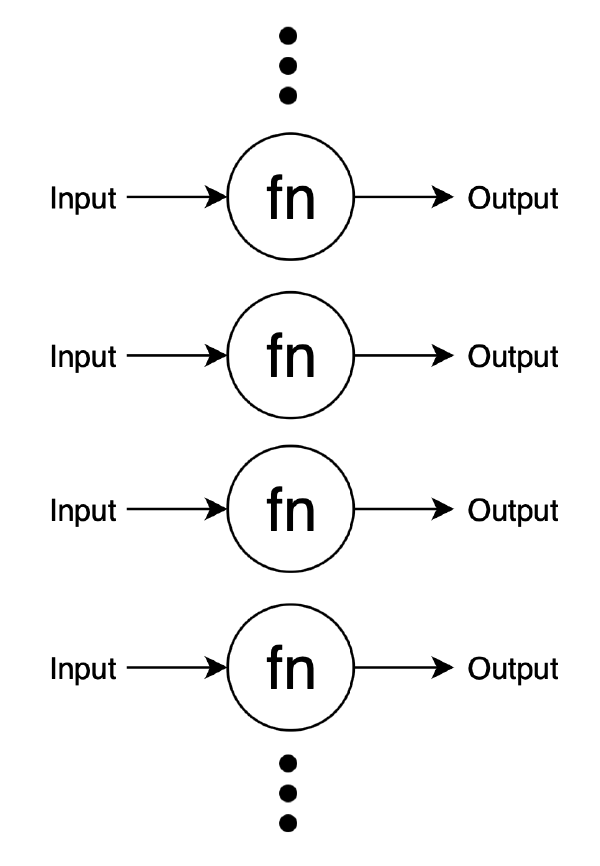
서버를 복제할 수 있으면 다음과 같은 장점이 있다.
- Scaling Out: 서버에 트래픽이 증가하면, 트래픽 증가를 버틸 수 있을 만큼 서버를 더 만들기만 하면 된다.
- Fault Tolerance: 서버에 Crash가 발생하더라도, 다른 서버가 동일한 요청을 처리할 수 있다. 어차피 물리적 위치만 다른 같은 서버다.
- State Management: 서버마다 다른 상태를 가지고 있지 않기 때문에 상태 관리가 단순해진다.
Cons
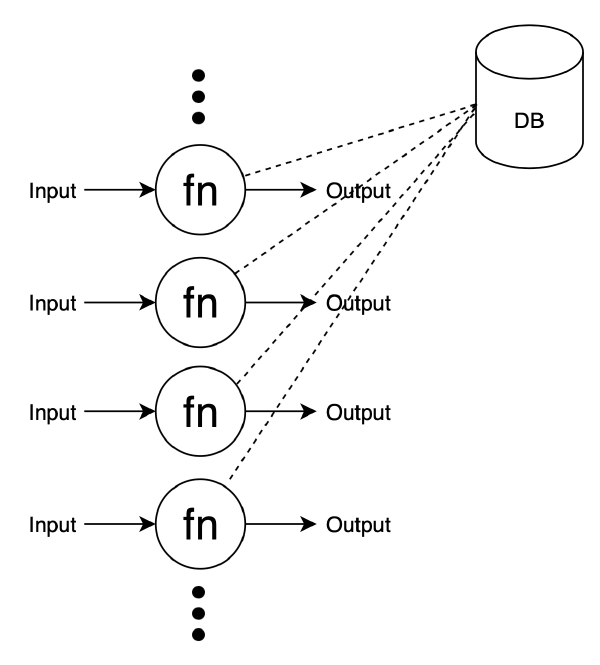
Stateless 서버라도 상태를 관리해야 한다면 어찌 되었든 외부에 상태를 저장해야 한다. 대표적인 것이 데이터베이스인데, 여러 서버가 동시에 같은 DB에 연결하면 병목현상이 발생할 뿐더러 시스템 전체의 성능과 작업의 우선도 등이 DB의 Locking Mechanism에 지배된다. 시스템의 가장 중요한 목표를 스스로의 로직이 아닌 외부의 매커니즘에 맡기는 것은 예측할 수 없는 문제를 야기할 수 있다.
Stateful Server
Pros
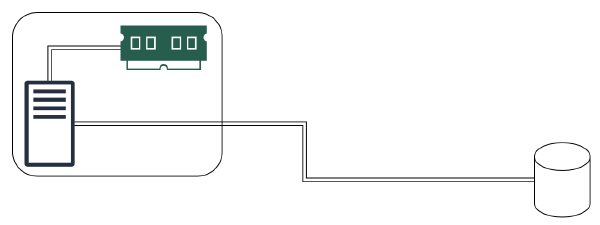
Stateful Server는 서버 프로세스에 직접 데이터를 저장한다. 따라서 데이터가 시스템의 메모리와 캐시에 저장되기 때문에 성능 상의 이점이 있다. 쓰기 읽기 작업이 빈번하게 일어날수록 이런 장점이 더욱 부각된다. 쿠키런 킹덤 개발팀에서는 유저의 요청에 따라 데이터의 변경이 빈번하게 일어나는 게임 어플리케이션의 특징을 고려해 Stateful 서버 구조를 채택했다.
Cons
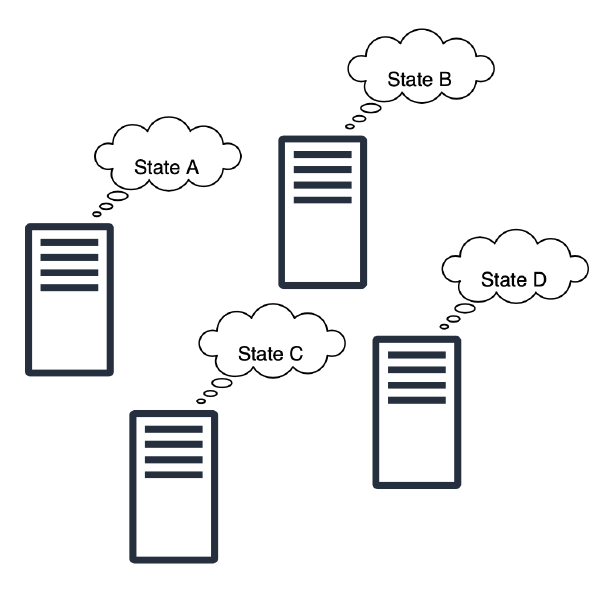
여러 상태가 여러 서버에 산재해서 존재하기 때문에 상태 관리가 복잡해진다. 그리고 서버에 상태가 존재하기 때문에, Stateless Server처럼 서버를 함부로 복제해 Scale Out하기 어려워진다. 같은 기능을 수행하는 서버라도 서버 프로세스의 상태가 다르면 같은 요청에 대해서 다른 응답을 내보낼 수 있기 때문이다.
쿠키런 킹덤 개발팀에서는 복잡한 상태 관리를 단순화하고 이해하기 쉽게 만들기 위해 Event Sourcing와 Actor Model을 이용했다. 이를 통해 서버가 구현해야 하는 기능을 명확하게 모델링할 수 있는데, 자세한 내용은 다음 편의 Event Sourcing에서 다루도록 하겠다.
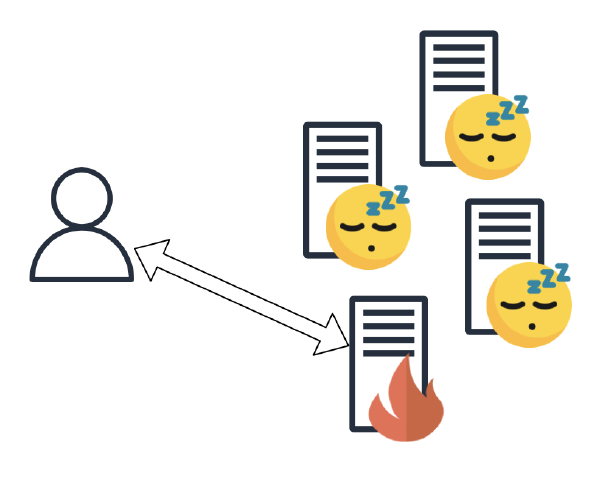
또한 같은 유저가 보낸 요청은 항상 같은 서버로 보내야 한다. 이렇게 서버의 부하를 분산시키는 데 제약조건이 생기게 된다. 해당 유저의 상태를 가지고 있는 서버만 그 유저의 요청을 처리할 수 있기 때문이다. 만약 요청의 수가 과도하게 많거나, 요청에 대해 응답을 생성하는 것이 너무 많은 리소스를 필요로 한다면 서버의 성능과 가용성에 문제가 생길 수 있다. 또한 한 유저의 요청을 계속 같은 서버가 처리할 수 있도록 하는 것도 시스템이 복잡해지는 원인이 된다.
Actor Model
쿠키런 킹덤 개발팀은 Stateful Server를 택했다. 게임 어플리케이션의 특성상 잦은 상태 변화를 관리할 수 있는 해결 방법이 필요했기 때문이다. 따라서 Stateful Server의 단점을 극복하기 위해 다른 솔루션이 필요하다. 쿠키런 킹덤 개발팀은 이 문제를 다음처럼 해결했다.
- 복잡해진 상태 관리를 단순화할 수 있어야 한다. ➡️ Actor Model을 이용해 이 문제를 해결했다.
- 부하를 효과적으로 분산하고, 한 유저가 보낸 요청을 계속 같은 서버가 처리할 수 있어야 한다. ➡️ Akka 프레임워크의 Cluster Sharding을 이용해 이 문제를 해결했다.
Actor Model은 무엇이고 Akka 프레임워크란 무엇인지 살펴보자. Akka 프레임워크는 Actor Model을 기반으로 어플리케이션을 작성하기 위해 고안된 프레임워크로 Actor Model을 도입해 어플리케이션을 작성할 때 마주칠 수 있는 문제를 해결하는 데 도움을 준다.
What is an Actor?
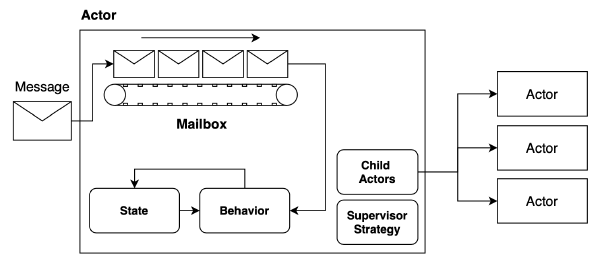
Actor Model은 분산환경과 동시성 컴퓨팅을 위해 고안된 모델이다. 액터는 다음 5개를 관리하는 컨테이너이며, Green Thread로 구현된다. (Green Thread란 OS를 이용해 구현된 Thread가 아닌 어플리케이션 단계에서 구현되는 경량화된 Thread를 말한다.)
- Mailbox: Message를 받는 Queue이다.
- Behavior: Message를 받았을 때 액터가 어떻게 행동하는지를 나타낸다.
- State: 액터가 내부적으로 관리하는 상태이다.
- Child Actors: 액터는 자식 액터를 가질 수 있다.
- Supervisor Strategy: 자식 액터의 Fault를 관리하는 방법이다.
Actor Model에서 가장 중요한 점은 Actor는 State와 Behavior를 외부로부터 캡슐화한다는 것이다. 외부에서는 액터와 상호작용할 수 있는 방법은 Mailbox에 Message를 보내는 것 뿐이다. OOP에서 객체가 오직 메서드를 통해 외부와 상호작용하는 것과 같은 이치다.
출처: https://getakka.net/articles/concepts/actor-systems.html
액터들은 액터 시스템이라는 수직적인(Hierarchical) 구조로 조직된다. 상위에 있는 액터들은 하위에 있는 액터에게 Task를 Sub-Task로 분할하여 나눠준다. 그리고 상위 액터들은 하위 액터들에서 발생하는 Fault를 처리하는 구조다.
Akka Cluster Sharding
Akka Cluster Sharding은 Actor Model 개념의 일부라기 보다는, Actor Model을 활용하기 위한 개념이다. 이전에 말했듯이 Stateful Server 구조에서 Scaling Out은 쉽지 않고, 따라서 별도의 솔루션이 필요하다.
Akka Cluster는 여러 개의 Akka Application을 관리하는 Scaling Out을 위한 솔루션이다. 큰 부하를 처리하기 위해서 노드의 수를 늘리는 방법이다.
Akka Cluster Sharding을 이용하면 특정 Actor가 Cluster 상에 어떤 노드에 존재하는지 신경쓰지 않아도 된다. Cluster Sharding는 메시지를 받는 액터를 알아서 찾아주고 연결해준다. 또한 노드의 부하를 클러스터 전체에 배분하고 노드를 추가하고 제거하는 작업을 수행한다. Akka Cluster의 복잡한 환경을 추상화해주는 도구라고 보면 될 것 같다.
Akka Cluster, Pros and Cons
여러 개의 노드가 운영되다보니 하나의 노드가 죽어도 다른 노드들이 작업을 계속 진행할 수 있으니 서버가 안정적으로 운영된다. 기술적인 용어로 단일실패지점(Single Point of Failure)가 없다는 말이다. 그리고 요구사항들을 액터로 모델링하고 Cluster Sharding을 이용하면 되기 때문에 기능구현이 쉬워지며 부하가 커지더라도 노드를 늘려서 대응할 수 있다.
더불어 기능을 수행하는 객체가 액터로 모델링되기 때문에 동시성에 대한 염려없이 상태관리가 명확해진다. 상태 관리에 액터 이외의 매커니즘이 필요하지 않기 때문이다. 상태 관리를 위해 DB Transaction을 이용한다든지 하는 일이 없다.
그러나 액터는 유연한 모델이 아니다. 어플리케이션에 필요한 모든 요구사항을 액터로 구현하는 것은 불가능한 일이다. 자칫하면 한 액터에 너무 많거나 큰 작업을 할당해 (액터의 메모리 제한이나 처리능력을 넘어서서) 액터가 죽어버리거나 병목현상이 발생할 수도 있다. 현명하게 다른 방법을 이용하는 것이 좋은 방법이다.
또한 이런 식으로 시스템을 구성하면 필연적으로 시스템을 이해하기 어려워지고 운영 난이도가 높아진다. 분산환경에서 전체 노드를 한번에 일률적으로 관리할 수가 없기 때문에 생기는 어려움이 있다. 예를 들어 한 노드는 업그레이드됐는데 다른 노드는 아직 되어 있지 않고(버전 불일치) 버전이 다른 노드 간 메시지가 compatible하지 않다면 오류가 발생하게 된다. Stateless라는 단순명확한 서버구조의 강점을 포기하고 다른 이점을 취한 결과라고 볼 수 있다.
마치면서
지금까지 Stateless, Stateful, Actor Model의 개념을 살펴보고, 추가적으로 Akka Cluster Sharding이 하는 일을 훑어봤다. 다음에는 CRUD와 Event Sourcing에 대해 정리해보자. F#의 MailboxProcessor를 통해 Actor 모델을 실습해보는 것도 좋을 것 같다.